Actualmente, las soluciones tecnológicas nos permiten hablar de reconocimiento facial y de detección de emociones como si nos refiriéramos a una actividad común.
¿Cómo funcionan?
Estas herramientas son capaces de detectar a una persona adormecida usando puntos de referencia faciales como una entrada de una red neuronal.
Una red neuronal convolucional 3D, en este caso, hace sonar una alarma para despertar al usuario y evitar algún tipo de accidente.
La idea es obtener un grupo de fotogramas de una webcam y luego extraer de ellos los puntos de referencia faciales, específicamente la posición de ambos ojos; luego, pasar estas coordenadas al modelo neural para obtener una clasificación final que nos dirá si el individuo está despierto o quedándose dormido.
Metodología
Trabajos recientes han demostrado que el reconocimiento de actividades se puede lograr con redes neuronales convolucionales 3D o Conv3D, debido a la capacidad de analizar no sólo un fotograma, sino un grupo de ellos. Este grupo de fotogramas consiste en un video corto donde se encuentra la actividad.
Habiendo dicho eso y considerando la somnolencia como una actividad que puede estar contenida en un video, tiene sentido usar Conv3D para tratar de predecir la somnolencia.
El primer paso es extraer un fotograma de una cámara, en nuestro caso una webcam. Una vez que tenemos el fotograma, usamos una biblioteca de Python llamada dlib donde se incluye un detector de hito facial; el resultado es una colección de coordenadas “x”, “y” que indican dónde están los puntos de referencia faciales.
Incluso cuando obtenemos una colección de puntos, sólo nos interesa la posición de los ojos, por lo que vamos a mantener sólo los doce puntos que pertenecen a los ojos.
Hasta ahora, tenemos los hitos faciales de un fotograma. Sin embargo, queremos darle a nuestro sistema el sentido de la secuencia, y para hacerlo, no estamos considerando fotogramas individuales para hacer nuestra predicción final, es mejor tomar un grupo de ellos.
Consideramos que analizar un segundo de video a la vez es suficiente para hacer buenas predicciones de somnolencia. Por lo tanto, mantenemos la detección de diez puntos de referencia faciales, que es equivalente a un segundo de video; luego, los concatenamos en un patrón que es una matriz con la forma (10, 12, 12); 10 fotogramas con 12 puntos en coordenadas “x” y 12 puntos en coordenadas “y”. Esta matriz es la entrada de nuestro modelo Conv3D para obtener la clasificación final.
Arquitectura
La cámara web siempre transmite video, pero analizamos un fotograma cada 0.1 segundos hasta que alcanzamos 10 muestras, el equivalente a 1 segundo, para extraer los puntos de referencia del rostro y mantener sólo los puntos correspondientes a ambos ojos.
Agrupamos los puntos con una superposición de siete unidades, lo que significa que agrupamos los puntos del fotograma uno al diez, el siguiente grupo se forma desde el punto del fotograma cuatro hasta el fotograma trece.
Una vez que tenemos un grupo de puntos de ojos (coordenadas x, y), los pasamos a nuestro modelo neuronal para obtener una clasificación, cuyo resultado puede ser [1, 0] que representa “despierto”, o [0, 1] que representa “soñoliento”. En otras palabras, estamos analizando la transmisión de la cámara web en partes pequeñas para obtener una predicción de la somnolencia cada segundo.
Resultados
Entrenamos nuestro modelo final sólo por 200 etapas, el optimizador utilizado para el entrenamiento de este modelo fue ADAM.
Por supuesto, lo intentamos con muchos otros modelos, pero el mejor resultado es el que se muestra aquí.
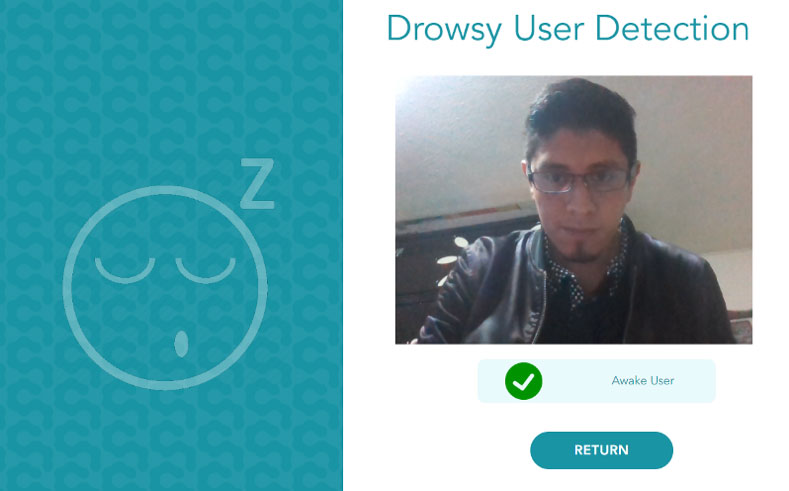
El resultado final de este trabajo es un front-end donde se muestra la cámara web del usuario. La transmisión se analiza cada segundo, y la predicción “somnoliento” o “despierto” se muestra debajo del video.
Como una característica adicional en nuestro ejemplo final, si el usuario es detectado como “somnoliento”, el sistema dispara una alarma sonora.
Para más experimentos, la solución propuesta aquí puede extenderse fácilmente para trabajar en un smartphone o incluso en un sistema integrado que ejecute una distribución de Ubuntu como la conocida raspberry pi.
Por Crystian Gil Morales, Senior AI Engineer para el everis AI Digital Lab